
En clair, quand on parle de scraper Google Maps, on parle d'utiliser des outils automatisés pour aspirer toutes les infos utiles des fiches d'entreprises : nom, téléphone, site web, avis, etc. C'est une technique redoutable pour transformer la plus grande base de données de commerces au monde en une liste de prospects prête à l'emploi, sans se fatiguer avec la saisie manuelle.
Pourquoi scraper Google Maps change vraiment la donne
Pour une équipe commerciale ou marketing, ce n'est pas juste un gadget technique. C'est un véritable levier de croissance.
Imaginez un instant : vous pourriez générer des listes de prospects ultra-ciblées en quelques minutes, analyser la concurrence quartier par quartier, ou encore enrichir votre CRM avec des données toujours à jour. Le scraping transforme cette gigantesque base de données publique en une mine d'or pour le business.
Quelques exemples concrets pour bien comprendre
Le vrai pouvoir de cette méthode, c'est ce qu'on en fait sur le terrain. Les possibilités sont immenses et ouvrent la porte à des stratégies d'acquisition très fines.
Par exemple :
- Une agence marketing pourrait lister tous les commerces d'une ville avec une note sous les 3,5 étoiles pour leur vendre une prestation de gestion d'e-réputation.
- Un fournisseur de logiciels de caisse irait cibler tous les restaurants qui viennent d'ouvrir dans une région pour leur présenter sa solution.
- Une boîte de services B2B pourrait cartographier l'ensemble des agences immobilières d'une zone précise pour affiner sa prospection locale.
Cette précision permet de laisser tomber la prospection de masse pour des campagnes chirurgicales, où chaque contact est déjà pré-qualifié.
La question n'est plus de savoir si l'on peut trouver des prospects, mais plutôt à quelle vitesse et avec quelle précision on peut les identifier. Le scraping de Google Maps est la réponse directe à ce défi.
D'ailleurs, cette technique a explosé en France ces dernières années. Une étude récente a montré que plus de 70 % des entreprises françaises spécialisées dans la génération de leads s'appuient sur des outils de scraping pour extraire des données locales. C'est logique : tout le monde cherche des données fiables pour mieux cibler, segmenter et comprendre la concurrence.
En automatisant cette collecte, vous dégagez un temps fou pour vos équipes. Un temps qu'elles peuvent enfin consacrer à des tâches qui comptent vraiment, comme personnaliser l'approche commerciale. Pour aller plus loin, notre guide sur l'utilisation de Google Maps pour la génération de leads vous montre comment transformer ces données brutes en véritables opportunités de business.
Choisir votre approche de scraping

Pour collecter les données de Google Maps, vous avez deux grandes options sur la table. Chacune avec ses règles, ses coûts et ses avantages. Votre choix va dépendre de vos compétences techniques, de votre budget et, surtout, de l'envergure de votre projet.
D'un côté, il y a la voie officielle, celle que Google vous propose : l'API Google Places. C'est la solution légitime et supportée par Google, donc elle est fiable, stable, et vous garantit un accès aux données sans risquer de vous faire bloquer. Le hic, c'est que cette tranquillité a un prix.
L'API Google Places, une option coûteuse et limitée
L'API fonctionne sur un modèle de paiement à la requête. Chaque recherche, chaque détail que vous demandez sur une fiche est facturé. Pour un besoin très ponctuel, ça passe. Mais si votre objectif est de trouver des milliers de prospects, la facture peut grimper très, très vite.
Et ce n'est pas tout. L'API impose des contraintes techniques assez frustrantes. Une seule requête ne vous donnera qu'une vingtaine de résultats, avec un plafond strict de 60 résultats par recherche. Pour aller au-delà, il faut ruser : découper la zone de recherche en petits carrés et multiplier les appels. Autant dire que ça devient vite un casse-tête.
En bref, l'API est une bonne solution pour des intégrations spécifiques ou des besoins très ciblés. Mais pour la prospection à grande échelle, on se sent vite à l'étroit.
Les outils de scraping spécialisés, la flexibilité avant tout
De l'autre côté du ring, on trouve les outils de scraping. L'idée est simple : utiliser un logiciel qui se comporte comme un humain pour extraire les informations directement depuis le site de Google Maps. C'est de loin la méthode la plus souple et la plus puissante pour récupérer de gros volumes de données.
Le principal avantage, c'est la richesse des informations. Là où l'API s'arrête, un bon scraper va chercher :
- La totalité des avis clients, pas juste les derniers.
- Les photos publiées par les utilisateurs.
- Les horaires d'affluence, une mine d'or pour évaluer l'activité d'un commerce.
- Toutes les informations cachées dans les descriptions.
Cette approche permet de faire sauter la limite des 60 résultats et de collecter des milliers de fiches en une seule fois. Pour une équipe commerciale qui doit alimenter son CRM, la différence est colossale.
Un bon outil de scraping ne se contente pas d'extraire des données, il les structure pour vous. Il transforme le chaos d'une page web en un fichier Excel propre, prêt à être intégré dans votre CRM.
Bien sûr, cette flexibilité a une contrepartie. Développer son propre scraper est techniquement complexe. Google déploie constamment des protections pour détecter les robots, comme les blocages d'IP et les CAPTCHAs. Pour passer à travers, il faut une infrastructure solide avec des proxies rotatifs et des systèmes pour résoudre les CAPTCHAs.
Heureusement, des solutions SaaS comme Scraap.ai gèrent toute cette complexité pour vous. Vous profitez de la puissance du scraping sans vous soucier de la maintenance technique.
Pour vous aider à y voir plus clair, voici une comparaison rapide.
Comparatif des approches de scraping sur Google Maps
Ce tableau compare les caractéristiques principales de l'API Google Places et des outils de scraping spécialisés pour aider à la décision.
| Critère | API Google Places (Officielle) | Outils de Scraping (Tiers) |
|---|---|---|
| Coût | Élevé et basé sur l'usage (paiement par requête) | Maîtrisé, souvent par abonnement fixe |
| Volume de données | Très limité (60 résultats max par recherche) | Potentiellement illimité |
| Richesse des infos | Données de base (nom, adresse, téléphone) | Données complètes (avis, photos, affluence...) |
| Complexité technique | Modérée à élevée pour l'intégration | Élevée si fait maison, nulle avec un outil SaaS |
| Fiabilité | Très haute (voie officielle) | Dépend de la qualité de l'outil et de l'infrastructure |
Le choix est donc assez clair : si vous avez besoin de données complètes, à jour et en grande quantité pour votre prospection, les outils de scraping sont la meilleure option. Ils offrent un retour sur investissement bien supérieur pour la génération de leads.
Comment fonctionne un scraper Google Maps, concrètement ?
Pour faire simple, imaginez un robot qui navigue sur Google Maps à votre place, mais à une vitesse fulgurante. Ce robot, le scraper, ne regarde pas l'écran comme nous. Il lit directement le code source de la page pour en extraire les informations qui nous intéressent.
La logique est assez directe, même si l'exécution peut vite devenir technique. Tout part d'une requête HTTP, la même que votre navigateur envoie quand vous tapez "plombiers à Lyon" dans la barre de recherche. Le scraper automatise simplement cet envoi.
En réponse, Google ne retourne pas une jolie carte interactive, mais un énorme fichier de code HTML. C'est le squelette brut de la page de résultats, qui contient tout le texte, les liens et la structure des fiches d'entreprises. Et c'est là que le vrai travail du scraper commence.
Décoder la structure de la page
Un scraper efficace est doté d'un "parser" (un analyseur syntaxique). Son job ? Passer au peigne fin ce bloc de code HTML pour y repérer des motifs, des balises spécifiques qui encadrent les données que l'on veut récupérer. Par exemple, le nom d'une entreprise pourrait être dans une balise <h1> avec une classe CSS bien précise comme class="font-headline-large".
Avant de coder quoi que ce soit, le développeur doit donc jouer au détective. Il inspecte manuellement le code source d'une page de résultats pour identifier les "sélecteurs CSS" ou les "chemins XPath". Ce sont en quelque sorte les adresses uniques qui mènent à chaque information.
- Le nom de l'entreprise ? Souvent dans une balise de titre (
h1,div...). - L'adresse postale ? Généralement dans une
divaccompagnée d'une icône de localisation. - Le numéro de téléphone ? Dans un lien cliquable particulier.
Une fois que ces "adresses" sont listées, le scraper peut être programmé pour aller chercher, fiche après fiche, le contenu de ces balises spécifiques.
Pour vous donner une idée, voici à quoi ça ressemble en pseudo-code Python avec une librairie comme BeautifulSoup. L'objectif ici est de récupérer tous les noms d'entreprises affichés sur une page de résultats.
On importe les outils nécessaires
import requests
from bs4 import BeautifulSoup
L'URL de notre recherche sur Google Maps
url_recherche = "https://www.google.com/maps/search/plombiers+lyon"
On envoie la requête pour récupérer le code HTML de la page
reponse = requests.get(url_recherche)
html_contenu = reponse.text
On analyse ce code HTML avec BeautifulSoup
soup = BeautifulSoup(html_contenu, 'html.parser')
On cherche tous les éléments qui correspondent au sélecteur CSS du nom de l'entreprise
(Attention : ce sélecteur est un exemple, Google le modifie régulièrement !)
elements_noms = soup.find_all('div', class_='font-headline-medium')
On parcourt les résultats et on affiche le nom de chaque entreprise
for element in elements_noms:
print(element.get_text())
Ce petit script illustre bien la mécanique de base : on demande la page, on l'analyse, et on extrait les données en se fiant à des marqueurs dans le code. Dans la vraie vie, c'est évidemment plus complexe, car Google Maps utilise du code dynamique et des protections pour compliquer la tâche.
D'ailleurs, si on regarde la documentation de l'API officielle de Google, on voit comment les données sont organisées côté serveur. Le scraping, lui, ne fait que reconstruire une structure similaire en partant de ce qui est affiché à l'écran.
Cette image montre comment Google organise les informations en interne. Le scraping vise à reconstituer cette même logique à partir du code HTML de la page.
Le défi de la pagination
Le premier vrai casse-tête, c'est la pagination. Une recherche sur Google Maps n'affiche qu'une vingtaine de résultats au départ. Pour en voir plus, il faut scroller ou cliquer sur "Page suivante". Un scraper doit absolument savoir faire ça.
Sans une gestion correcte de la pagination, votre outil s'arrêtera après les 20 premières fiches, vous laissant avec une fraction seulement des données disponibles.
Un scraper bien conçu est donc programmé pour :
- Extraire toutes les données de la page actuellement chargée.
- Repérer le mécanisme qui charge la suite des résultats (souvent, un scroll qui déclenche un appel JavaScript en arrière-plan).
- Simuler cette action de "scroll" ou de "clic" pour afficher la nouvelle vague de résultats.
- Répéter ce cycle jusqu'à ce qu'il n'y ait plus rien à charger.
Cette boucle est ce qui permet de passer d'une vingtaine de contacts à plusieurs centaines, voire milliers, pour une seule recherche.
Savoir gérer la pagination, c'est ce qui fait la différence entre un petit script amateur et un véritable outil de web scrape Google Maps capable de construire des listes de prospection massives. C'est un vrai défi technique, car il faut comprendre comment la page interagit avec le navigateur.
Pour résumer, un scraper Google Maps simule intelligemment la navigation humaine, analyse le code source reçu, identifie les bonnes données grâce à des sélecteurs précis, et sait naviguer entre les pages pour garantir une collecte exhaustive. Le concept peut sembler simple, mais le mettre en œuvre à grande échelle demande une vraie expertise pour contourner les obstacles techniques et les protections mises en place.
Déjouer les obstacles du scraping à grande échelle
Extraire les informations d'une dizaine de fiches Google Maps ? C'est un jeu d'enfant. Mais quand on passe à l'échelle supérieure et qu'on vise des milliers, voire des dizaines de milliers de contacts, les règles du jeu changent brutalement. Ce qui était une simple collecte se transforme en une véritable bataille technique contre les mécanismes de protection de Google.
Le premier mur que vous allez rencontrer, c'est le blocage de votre adresse IP. Envoyez quelques centaines de requêtes un peu trop vite, et les serveurs de Google vous repéreront comme un robot. Votre IP sera alors mise sur liste noire, temporairement ou définitivement. Et là, c'est la fin de la partie pour votre collecte.
Ce processus, de la requête initiale à l'extraction finale, peut être visualisé simplement.
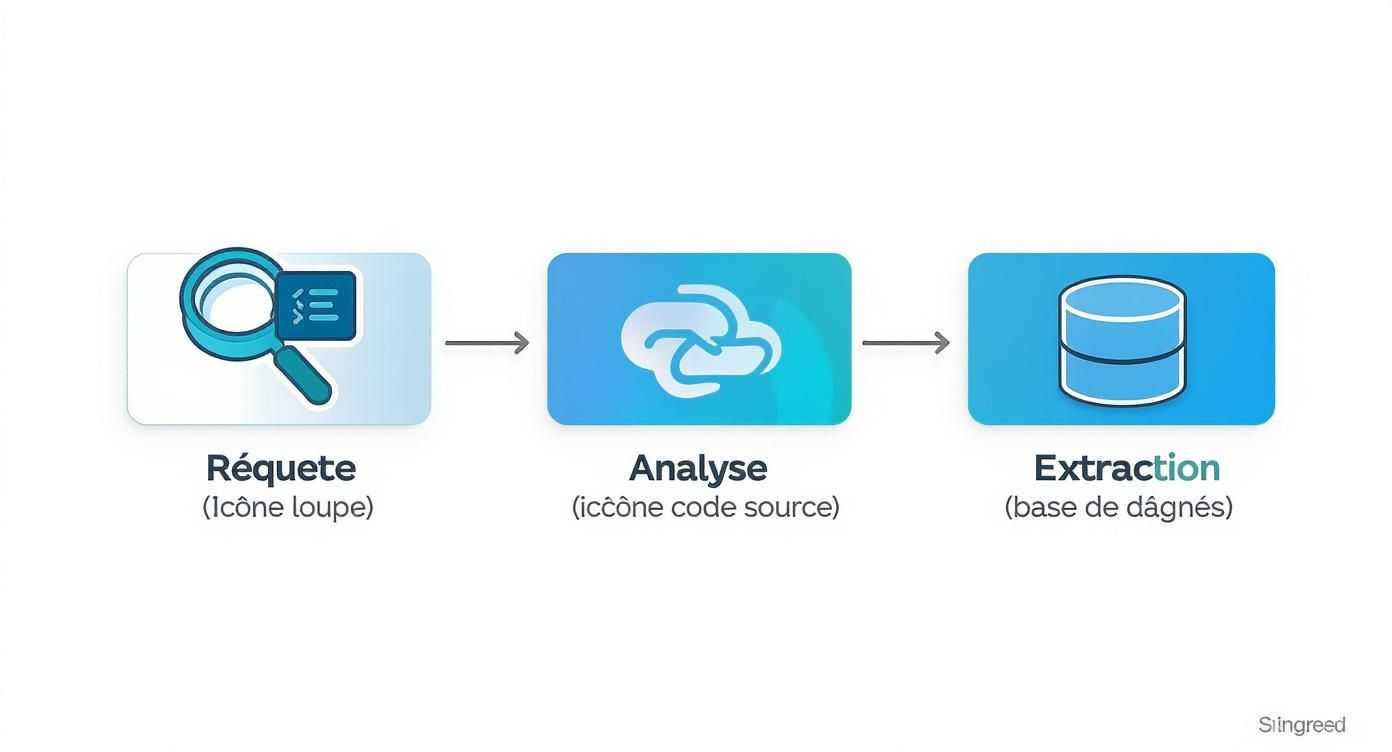
Ce schéma met en lumière le moment critique : l'analyse de la réponse du serveur. C'est précisément à cette étape que les blocages surviennent et que tout peut s'arrêter.
L'indispensable infrastructure de proxies
Pour contourner ce premier obstacle, une infrastructure de proxies rotatifs n'est pas une option, c'est une nécessité. Un proxy, c'est tout simple : il agit comme un intermédiaire. Au lieu d'envoyer les requêtes depuis votre propre IP, votre scraper passe par un serveur tiers.
La vraie puissance vient de la rotation. Un bon système de proxies rotatifs utilise un vaste réservoir d'adresses IP différentes. À chaque nouvelle requête (ou toutes les quelques requêtes), l'IP change. Du point de vue de Google, ces requêtes semblent provenir de centaines d'utilisateurs distincts, ce qui rend la détection bien plus difficile.
Il existe deux grandes familles de proxies :
- Les proxies de datacenters : Ils viennent de serveurs cloud. Ils sont rapides, abordables, mais leurs plages d'IP sont souvent connues et donc plus faciles à repérer pour Google.
- Les proxies résidentiels : Ce sont de vraies adresses IP, celles attribuées à des particuliers par leur fournisseur d'accès. Forcément plus chers, ils sont aussi beaucoup plus discrets, car ils se fondent parfaitement dans le trafic d'utilisateurs normaux.
Pour un projet de web scrape Google Maps à grande échelle, la clé du succès est souvent un mélange intelligent des deux, ou l'utilisation exclusive de proxies résidentiels si le budget le permet.
La gestion des redoutables CAPTCHAs
Même avec la meilleure armée de proxies, vous tomberez fatalement sur le deuxième grand obstacle : les CAPTCHAs. Vous savez, ces petites énigmes visuelles – "Cliquez sur toutes les images de feux de circulation" – conçues pour vérifier que vous êtes bien un humain.
Quand un scraper se heurte à un CAPTCHA, son travail s'arrête net. Incapable de résoudre l'énigme, il ne peut plus accéder au contenu. C'est le point de rupture classique pour la plupart des projets de scraping amateurs.
Un scraper qui ne gère pas les CAPTCHAs est un scraper qui ne fonctionnera pas longtemps. C'est une compétence cruciale pour assurer la continuité de la collecte à grande échelle.
Pour s'en sortir, il y a deux approches. La première, c'est de déléguer. Des services de résolution de CAPTCHA comme 2Captcha ou Anti-Captcha utilisent des humains ou des IA pour résoudre ces énigmes pour vous, moyennant un petit coût par résolution. Votre scraper envoie le CAPTCHA, attend la solution, et continue son chemin.
La seconde approche est préventive : il s'agit d'adopter un comportement qui minimise les chances de déclencher un CAPTCHA. Pour creuser le sujet, jetez un œil à notre guide sur l'extraction de données web sans être bloqué par les CAPTCHAs. Il regorge de techniques pour rester sous les radars.
Simuler un comportement humain crédible
La dernière pièce du puzzle, c'est de rendre votre scraper aussi humain que possible. Les algorithmes de Google ne se contentent pas de compter le nombre de requêtes pour vous identifier. Ils analysent des dizaines de signaux comportementaux.
Pour passer inaperçu, il faut donc intégrer des variations et de l'aléatoire dans les actions de votre scraper.
Varier les User-Agents
Le User-Agent, c'est la "carte d'identité" de votre navigateur (par exemple, "Chrome sur Windows 10"). Un scraper qui utilise en permanence le même User-Agent est suspect. La bonne pratique est de constituer une liste de User-Agents récents et d'en changer aléatoirement à chaque nouvelle session ou requête.
Ajouter des délais aléatoires
Un humain ne clique pas sur un lien toutes les 200 millisecondes, sans exception. Votre scraper doit donc marquer des pauses. Mais attention, un délai fixe (attendre 2 secondes à chaque fois) est tout aussi suspect. Le secret, c'est d'utiliser des délais aléatoires, par exemple en attendant entre 1,5 et 4 secondes. Cela imite bien mieux le rythme irrégulier d'une vraie personne.
En combinant des proxies robustes, une bonne gestion des CAPTCHAs et une simulation de comportement crédible, vous transformez un simple script en une machine de collecte de données capable de tourner efficacement, sur la durée.
Aborder le scraping : les règles du jeu à connaître
Se lancer dans le scraping de Google Maps sans se pencher sur les aspects légaux et éthiques, c'est un peu comme naviguer en mer sans boussole. C'est un point souvent mis de côté, mais les conséquences d'une telle négligence peuvent être lourdes. Pour que votre projet de web scrape Google Maps ne tourne pas au cauchemar, il faut bien comprendre le terrain de jeu.
La première règle est simple et vient directement de Google. Leurs conditions d'utilisation interdisent formellement l'extraction automatisée des données de leurs services, Maps y compris. Si vous vous faites attraper, pas de panique, vous n'irez pas en prison. Le risque est purement technique : Google va tout simplement bloquer vos outils et vos adresses IP. Et croyez-moi, ils sont devenus experts pour repérer les scrapers un peu trop naïfs.
Le RGPD, un enjeu incontournable
Le vrai sujet sensible, c'est le Règlement Général sur la Protection des Données (RGPD). C'est là que les choses se corsent. Dès qu'une information que vous collectez peut être liée à une personne physique (un nom, un email, le nom du gérant d'une petite boutique), elle devient une donnée personnelle. Point.
Le fait que ces données soient affichées publiquement sur Google Maps ne change absolument rien à l'affaire. Leur collecte et leur traitement systématiques sont très encadrés. En cas de non-respect, les amendes peuvent être salées : jusqu'à 4 % du chiffre d'affaires mondial d'une entreprise. Mieux vaut donc marcher sur des œufs.
La vraie question n'est pas "cette donnée est-elle publique ?", mais "est-elle personnelle ?". Si la réponse est oui, le RGPD s'applique sans exception, scraping ou pas.
L'idée n'est pas de collecter à l'aveugle tout ce qui bouge. Il faut cibler intelligemment les informations qui ont un intérêt légitime et réel pour votre projet.
Une approche pragmatique pour rester dans les clous
Comment faire, alors ? Une stratégie maline consiste à se concentrer sur les données qui concernent les entreprises (personnes morales) plutôt que les individus.
Voici quelques réflexes à adopter pour scraper plus sereinement :
- Priorisez les données B2B. Concentrez-vous sur le nom de l'entreprise, son adresse, son numéro de téléphone standard et son site web. En général, ces informations ne sont pas considérées comme personnelles.
- Laissez de côté les infos trop personnelles. Évitez de vouloir à tout prix récupérer les noms des gérants, les adresses email personnelles (celles en @gmail.com ou @orange.fr) et tout ce qui touche à la sphère privée.
- Jouez la transparence. Si vous utilisez ces données pour prospecter, soyez clair sur leur origine. Et surtout, proposez un moyen simple et immédiat de se désinscrire. C'est la base.
- Ne conservez pas les données indéfiniment. Une fois votre objectif atteint, faites le ménage. Une base de données qui prend la poussière est un risque juridique inutile.
En suivant ces principes, vous ne faites pas disparaître le risque à 100 %, mais vous le diminuez drastiquement. Vous montrez surtout que vous avez une démarche professionnelle et respectueuse. Le scraping est un outil formidable, mais comme tout outil puissant, sa véritable valeur se mesure à l'intelligence et à l'éthique avec lesquelles on l'utilise.
La solution no-code : l'alternative pragmatique pour les équipes commerciales
Soyons honnêtes : pour la plupart des entreprises, se lancer dans le développement et la maintenance d’une infrastructure de scraping maison est un véritable casse-tête. C'est un projet à temps plein qui engloutit des ressources techniques et financières. Entre la gestion complexe des proxies, la résolution permanente des CAPTCHAs et les adaptations constantes aux changements de Google, l'effort est colossal.
Et surtout, il vous détourne de votre véritable objectif : vendre.
Heureusement, il existe une voie beaucoup plus directe. Les plateformes SaaS spécialisées dans le web scraping de Google Maps ont été créées justement pour gérer toute cette complexité à votre place. Ces outils permettent à n'importe qui, même sans aucune compétence technique, de récupérer des données fiables en quelques minutes. Le tout, sans écrire une seule ligne de code.
Le principe est simple : transformer un processus technique intimidant en une simple action stratégique. Au lieu de jongler avec des scripts Python et des serveurs, vous vous concentrez sur ce qui compte vraiment : définir votre client idéal.
Comment lancer une extraction en quelques clics ?
Avec une solution comme Scraap.ai, le processus devient radicalement plus simple. La question n'est plus comment scraper, mais qui scraper. L'interface est pensée pour vous guider de manière intuitive, étape par étape.
Le fonctionnement est presque déconcertant de simplicité :
- Définir la cible : Vous entrez simplement des mots-clés qui décrivent votre prospect, comme "restaurant Paris" ou "plombier Lyon".
- Préciser la zone géographique : Ciblez une ville, une région, ou dessinez un périmètre sur une carte pour une précision chirurgicale.
- Lancer la machine : Un clic, et la plateforme s'occupe de tout en arrière-plan.
L'interface est conçue pour être accessible à tous, comme vous pouvez le voir ci-dessous.
Cette approche visuelle élimine toute friction. Vous n'avez plus à vous soucier de la technique, vous pouvez vous concentrer à 100 % sur votre stratégie de prospection.
Une fois que vous avez cliqué sur "Démarrer", la plateforme gère automatiquement les proxies rotatifs et les CAPTCHAs. Vous n'avez même pas à y penser. Les données sont collectées, nettoyées, et structurées dans un fichier propre, prêt à être importé dans votre CRM. Souvent, ces outils vont même plus loin en enrichissant les contacts avec des informations cruciales, comme des adresses e-mail professionnelles.
L'approche no-code ne fait pas que simplifier le scraping, elle le démocratise. Elle met la puissance des données à grande échelle entre les mains de ceux qui en ont le plus besoin : les commerciaux et les marketeurs.
C'est sans doute la voie la plus rapide pour transformer les informations de Google Maps en leads qualifiés. Si cette méthode vous intéresse, notre article sur le no-code scraping explique comment extraire des données web sans se faire bloquer et vous donnera des stratégies concrètes pour maximiser vos résultats. C'est la solution idéale pour obtenir un retour sur investissement rapide, sans avoir à investir dans la technique.
Questions fréquentes sur le scraping de Google Maps
Vous vous posez sans doute quelques questions sur l'extraction de données depuis Google Maps. C'est tout à fait normal. Voici les réponses claires et directes aux interrogations les plus courantes que je rencontre.
Est-ce que je risque quelque chose à scraper Google Maps en France ?
C'est LA grande question. Pour faire simple, on navigue dans une zone un peu floue. D'un côté, les conditions d'utilisation de Google l'interdisent formellement. De l'autre, la loi française autorise l'extraction de données publiques. Le point de friction, c'est le RGPD dès qu'on touche à une donnée personnelle.
La meilleure stratégie, et la plus sûre, est de se concentrer uniquement sur les données d'entreprises (les personnes morales). Pensez "nom de la société", "adresse du siège", "numéro de téléphone standard". En restant sur ce terrain et en adoptant une démarche propre, on limite considérablement les risques.
Concrètement, combien de contacts je peux espérer récupérer ?
Tout dépend de la méthode. Si vous êtes un développeur aguerri avec une infrastructure qui tient la route (proxies, gestion des captchas, etc.), vous pouvez théoriquement viser des centaines de milliers de fiches. Mais c'est un travail à plein temps.
Pour la plupart des équipes commerciales, les outils SaaS sont bien plus réalistes.
L'avantage de ces plateformes, c'est qu'elles gèrent toute la complexité pour vous. Vous pouvez ainsi obtenir des milliers de leads qualifiés chaque mois sans jamais vous soucier d'une IP bannie ou d'un captcha bloquant. C'est le meilleur compromis entre le volume que vous pouvez extraire et la tranquillité d'esprit.
Quelles sont les données qui comptent vraiment pour ma prospection ?
La base, c'est bien sûr le nom de l'entreprise, le téléphone, le site web, l'adresse, et un coup d'œil sur la note moyenne et le nombre d'avis. C'est le kit de démarrage pour un premier contact.
Mais la vraie mine d'or, c'est l'enrichissement. Les meilleures solutions ne s'arrêtent pas là. Elles vont chercher les emails professionnels et les profils LinkedIn des décisionnaires au sein de ces entreprises. C'est ce qui transforme une simple ligne dans un fichier Excel en une véritable opportunité commerciale.
Arrêtez de copier-coller des informations manuellement. Passez à la vitesse supérieure. Avec Scraap.ai, vous pouvez construire des listes de prospects ultra-ciblées en quelques minutes, sans avoir à écrire une seule ligne de code. Découvrez par vous-même la puissance du no-code.


