
Dans un paysage B2B où la prospection manuelle est devenue un goulot d'étranglement, la capacité à collecter, enrichir et qualifier des leads à grande échelle est un avantage compétitif majeur. Les équipes commerciales passent encore un temps précieux à copier-coller des informations depuis LinkedIn, des annuaires ou des sites web, un processus non seulement chronophage mais aussi source d'erreurs. C'est ici que les outils de scraping entrent en jeu, non pas comme de simples extracteurs de données, mais comme de véritables moteurs d'automatisation pour la croissance. Ces plateformes permettent de transformer des heures de recherche en quelques clics, en construisant des listes de prospects ultra-ciblées, enrichies de coordonnées vérifiées et de signaux d'intention pertinents. Pour affiner votre stratégie de prospection et cibler les bonnes audiences, il est essentiel de savoir comment choisir ses mots-clés SEO, une étape souvent facilitée par l'analyse de données brutes. Cependant, face à une offre pléthorique, comment choisir la solution la plus adaptée à vos besoins ? Faut-il privilégier une approche no-code accessible, une API flexible pour les développeurs, ou une plateforme tout-en-un avec qualification intégrée ? Cet article vous propose un classement et une analyse détaillée de 12 outils de scraping incontournables, en se concentrant sur leurs fonctionnalités clés pour la génération de leads B2B : accessibilité, capacités d'enrichissement, conformité RGPD et intégrations CRM. Notre objectif : vous fournir un guide pratique, avec captures d'écran et liens directs, pour choisir l'outil qui alimentera efficacement votre pipeline commercial.
1. Scraap.ai
Meilleur outil de scraping no-code tout-en-un pour la génération de leads B2B
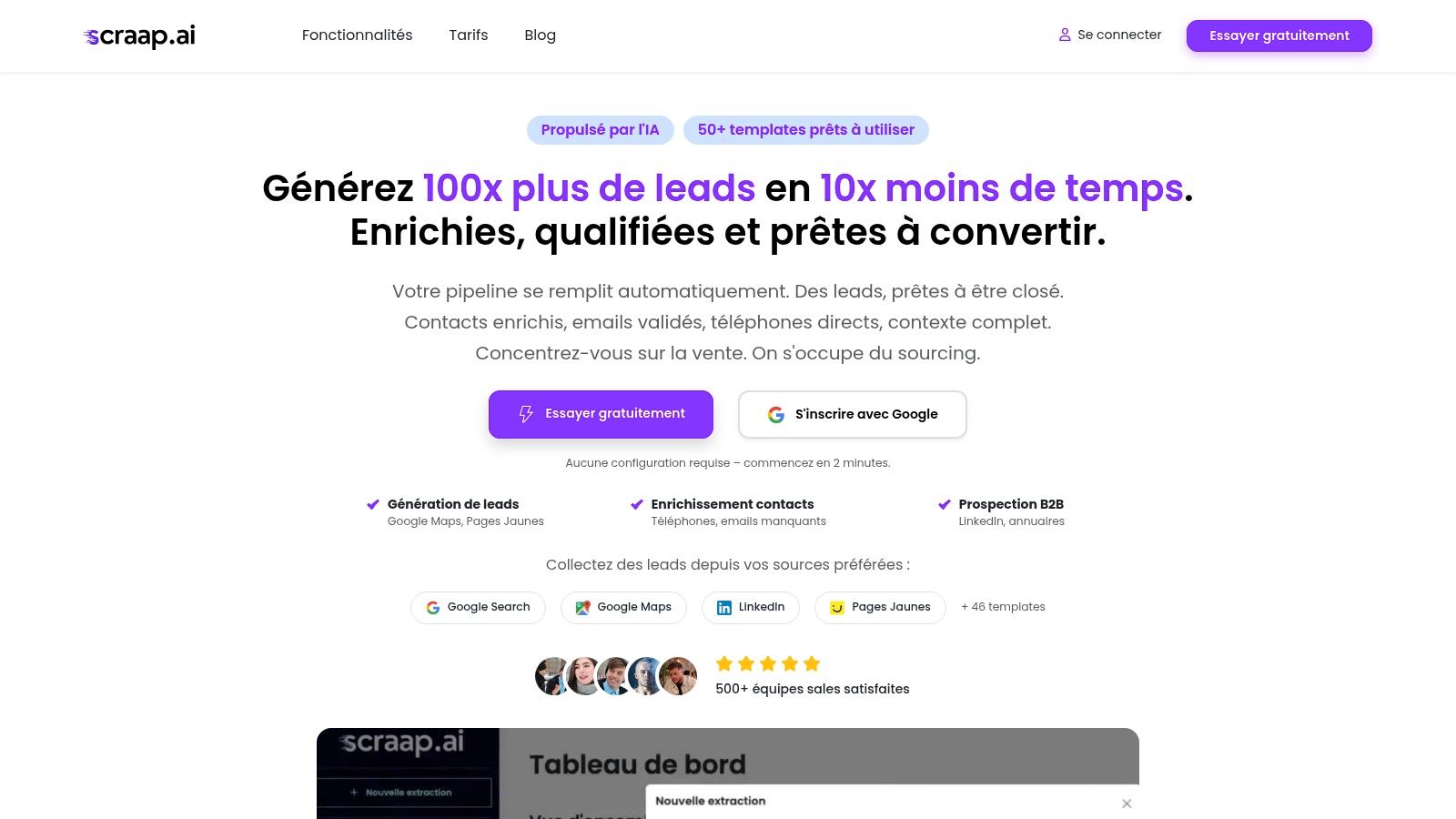
Scraap.ai s'impose comme une solution de premier plan parmi les outils de scraping en transformant la prospection B2B manuelle et chronophage en un flux de travail automatisé et intelligent. Cette plateforme française SaaS no-code permet aux équipes commerciales et marketing de construire des listes de prospects ultra-ciblées, enrichies et prêtes à l'emploi, sans aucune compétence technique. Son approche intégrée, combinant extraction, enrichissement et qualification en temps réel, en fait un choix stratégique pour alimenter un pipeline de vente de manière prédictible et scalable.
L'atout majeur de Scraap.ai réside dans son accessibilité et sa puissance. En quelques clics ou en copiant-collant une URL, vous pouvez lancer des extractions sur des sources clés comme Google Maps, LinkedIn Sales Navigator ou les Pages Jaunes. La plateforme s'appuie sur plus de 50 templates préconfigurés pour simplifier le processus, permettant un démarrage en moins de deux minutes.
Analyse des fonctionnalités et points forts
Ce qui distingue Scraap.ai, c'est sa capacité à aller bien au-delà de la simple collecte de données. Une fois les informations extraites, son intelligence artificielle entre en jeu pour combler les lacunes : elle trouve et valide les adresses email professionnelles, identifie les numéros de téléphone directs et complète les profils avec des données firmographiques (taille de l'entreprise, secteur, technologies utilisées). La plateforme intègre également des signaux d'intention, comme les récentes levées de fonds ou les offres d'emploi, pour un scoring précis des leads.
La robustesse technique est un autre pilier de l'offre. Scraap.ai est conçu pour traiter des volumes massifs de données (jusqu'à des centaines de milliers de pages simultanément) grâce à une infrastructure résiliente et des mécanismes anti-bot avancés (résolution de CAPTCHA, proxies premium, rotation d'IP). Cette fiabilité assure un taux de succès de collecte élevé et constant.
Pour qui et comment l'utiliser ?
Scraap.ai est particulièrement adapté pour :
- Les SDRs et équipes Sales Ops cherchant à automatiser la création de listes de prospection.
- Les Growth Marketers souhaitant alimenter leurs campagnes d'outreach avec des données fraîches et segmentées.
- Les fondateurs de startups et agences qui ont besoin de construire rapidement une base de prospects qualifiés.
Cas d'usage pratique : Une équipe commerciale peut cibler les "restaurants les mieux notés à Lyon" sur Google Maps, extraire les données, les enrichir automatiquement avec les emails des gérants, puis synchroniser la liste finale directement dans leur CRM HubSpot pour lancer une campagne personnalisée.
Avantages :
- Prise en main immédiate : Interface no-code et templates pour lancer une extraction en ~2 minutes.
- Workflow complet : Chaîne de valeur intégrée (extraction, enrichissement, qualification, synchronisation).
- Sécurité et conformité robustes : Hébergement en France, certifications (ISO 27001, SOC 2 Type II) et conformité RGPD.
- Technologie anti-bot performante : Maximise la réussite des extractions à grande échelle.
- Intégrations natives : Synchronisation fluide avec Salesforce, HubSpot, Pipedrive, Google Sheets, et plus via API.
Inconvénients :
- Tarification non publique : Les prix détaillés ne sont pas affichés, nécessitant une prise de contact pour obtenir un devis adapté à ses besoins.
- Dépendance aux sources externes : L'efficacité reste liée aux structures et politiques des sites ciblés.
Offre d'essai : Inscription sans carte bancaire avec 50 crédits offerts pour tester la plateforme.
Lien : Scraap.ai
2. PhantomBuster
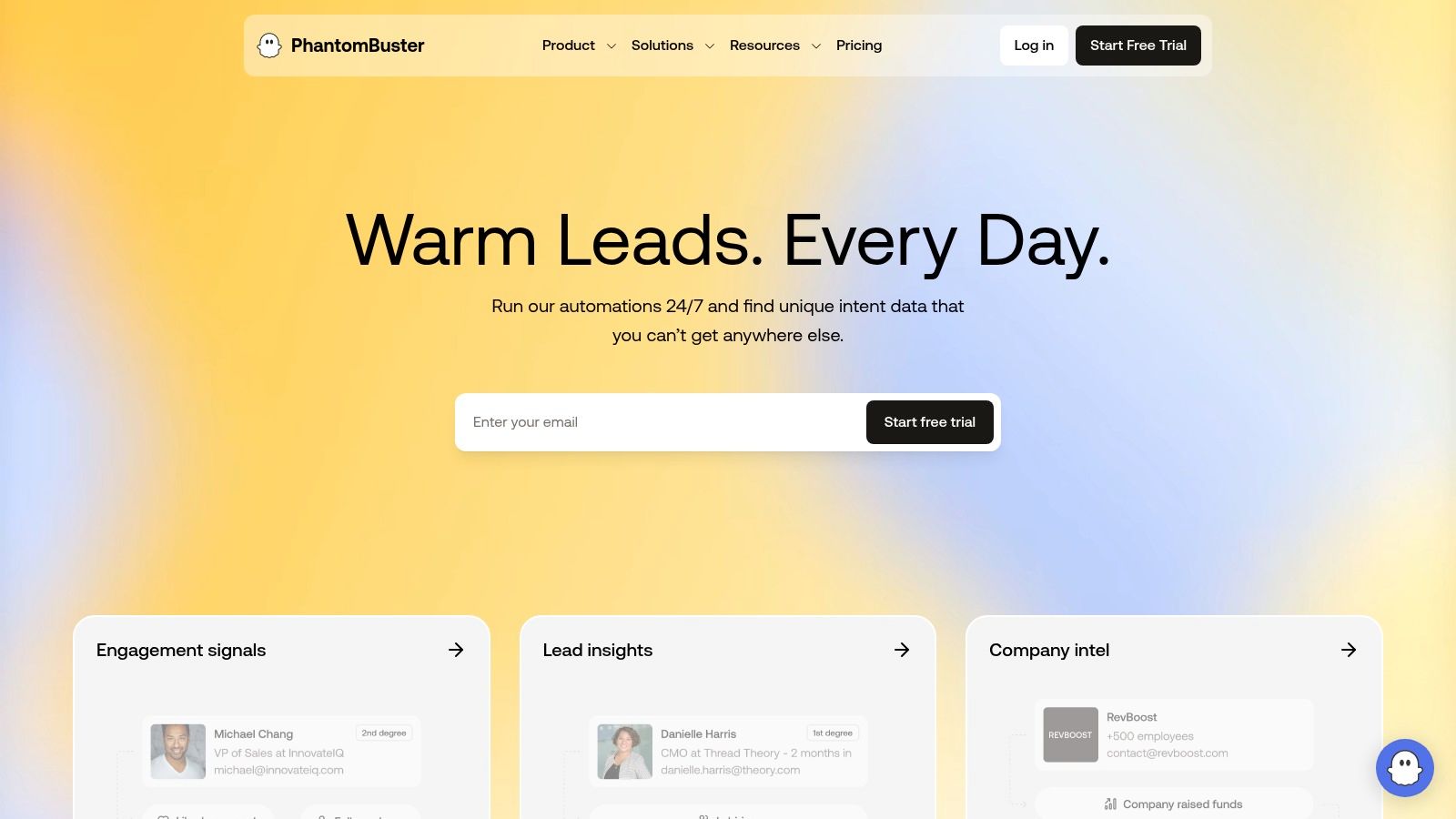
PhantomBuster est l'un des outils de scraping et d'automatisation les plus populaires sur le marché, particulièrement apprécié des équipes commerciales et growth. Sa force réside dans son approche "no-code" qui permet de déployer rapidement des actions d'extraction de données depuis les réseaux sociaux professionnels et de multiples autres sources. La plateforme fonctionne sur un système de "Phantoms", des scripts préconfigurés pour des tâches spécifiques comme extraire les membres d'un groupe LinkedIn ou les followers d'un compte X (anciennement Twitter).
Cette modularité permet de créer des workflows complexes en enchaînant plusieurs Phantoms. Par exemple, un utilisateur peut d'abord extraire une liste de profils depuis Sales Navigator, puis utiliser un autre Phantom pour enrichir ces profils avec leurs adresses email professionnelles, et enfin les exporter automatiquement vers une Google Sheet ou un CRM. L'interface est intuitive, guidant l'utilisateur à chaque étape de la configuration.
Caractéristiques et positionnement
PhantomBuster se distingue par son immense catalogue d'automatisations prêtes à l'emploi. Contrairement à des solutions plus techniques, il ne nécessite aucune connaissance en programmation. Son exécution dans le cloud assure une collecte de données continue, même lorsque votre ordinateur est éteint.
- Idéal pour : Les équipes SDR et les spécialistes du marketing qui ont besoin de résultats rapides sans dépendre d'une équipe technique.
- Fonctionnalités clés : Plus de 100 "Phantoms", workflows multi-étapes, planification des lancements, exécutions cloud, et enrichissement d'emails intégré.
- Limites à considérer : Le principal inconvénient réside dans les quotas. Les plans sont limités par un temps d'exécution mensuel et un nombre de "slots" (automatisations actives simultanément), ce qui peut devenir restrictif pour des opérations de scraping à très grande échelle.
Le plan gratuit est assez limité, notamment sur les exports, mais il est suffisant pour tester les fonctionnalités de base. L'outil est particulièrement puissant pour la prospection sur LinkedIn et Sales Navigator.
Site web : https://phantombuster.com
3. Captain Data
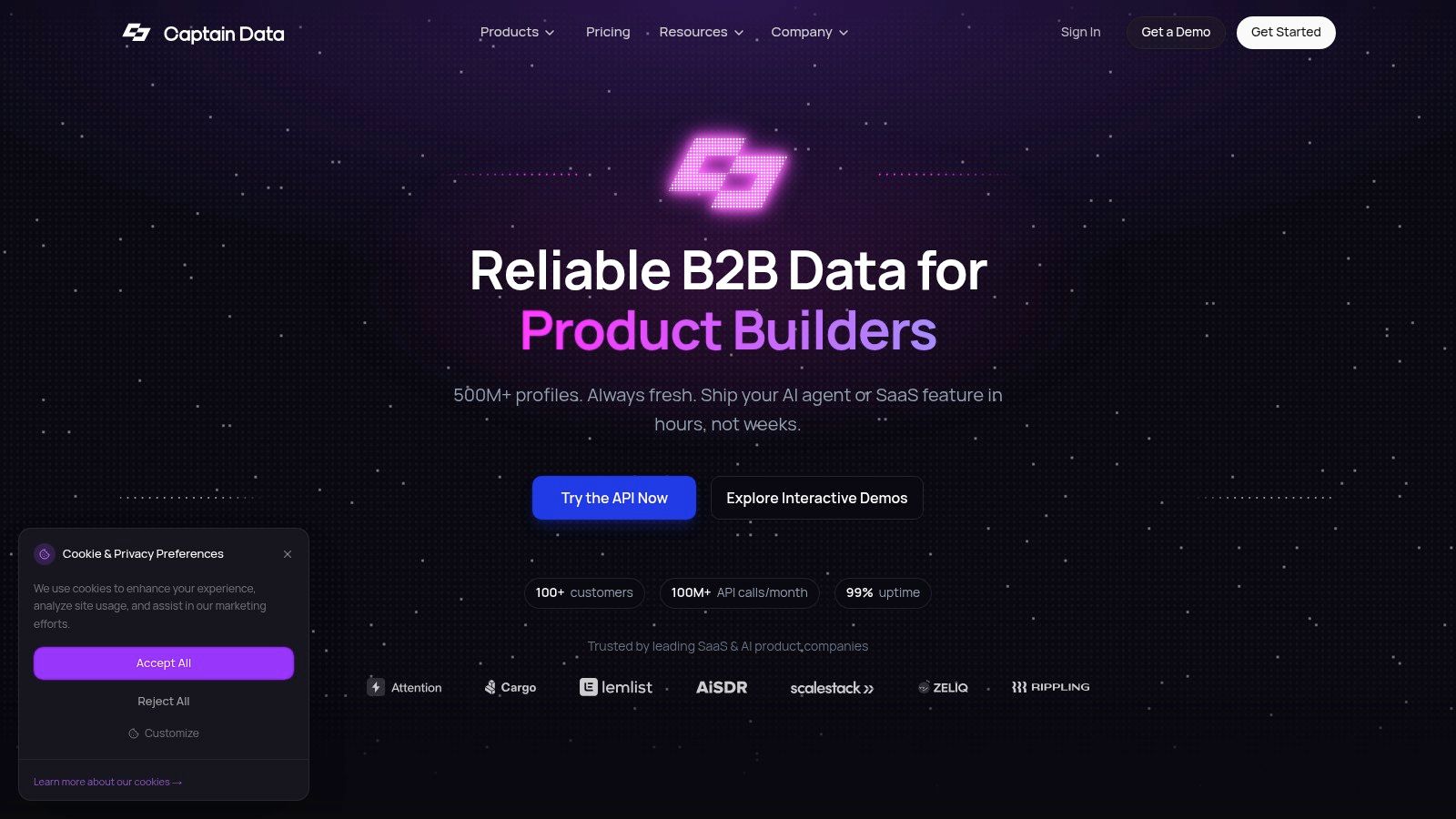
Captain Data est une plateforme d'automatisation et d'extraction de données B2B française qui se positionne comme un outil de choix pour les équipes Sales et RevOps. Contrairement à d'autres outils de scraping plus généralistes, sa force réside dans ses capacités d'intégration profonde avec les stacks de vente (CRM, outils d'enrichissement) et ses API puissantes conçues pour des opérations commerciales à grande échelle. La plateforme permet de créer des workflows pour rechercher, enrichir et qualifier des contacts et des entreprises à partir de sources comme LinkedIn, Google ou les sites web corporate.
L'approche de Captain Data est plus technique que celle d'un outil "no-code" grand public, mais elle offre en retour une flexibilité et une fiabilité supérieures. Les utilisateurs peuvent construire des chaînes d'automatisation complexes, par exemple pour monitorer des signaux d'achat (intent data) ou pour enrichir en temps réel les leads entrants directement dans leur CRM. La tarification basée sur des crédits à la consommation offre une prévisibilité des coûts pour les opérations data.
Caractéristiques et positionnement
Captain Data se distingue par son architecture orientée API et sa robustesse, ce qui en fait un allié pour structurer les processus de génération de leads. Il s'intègre nativement à des CRM comme HubSpot ou Salesforce, permettant une synchronisation fluide des données.
- Idéal pour : Les équipes Sales Ops et RevOps qui cherchent à automatiser leurs flux de données de prospection et à les intégrer directement dans leurs outils métier.
- Fonctionnalités clés : API "Search" et "Enrichment" pour personnes et entreprises, workflows prêts à l'emploi, intégrations CRM natives, monitoring d'intentions, support white-glove pour les gros volumes.
- Limites à considérer : Le modèle de tarification par crédits peut devenir coûteux pour les enrichissements massifs, notamment d'adresses email. De plus, les crédits non utilisés expirent à la fin de chaque période d'abonnement, ce qui incite à une consommation régulière.
La plateforme est particulièrement adaptée aux entreprises qui ont déjà une stratégie de prospection bien définie et qui ont besoin d'un outil fiable pour l'exécuter à grande échelle, avec une intégration poussée dans leur écosystème technologique.
Site web : https://www.captaindata.com
4. Apify
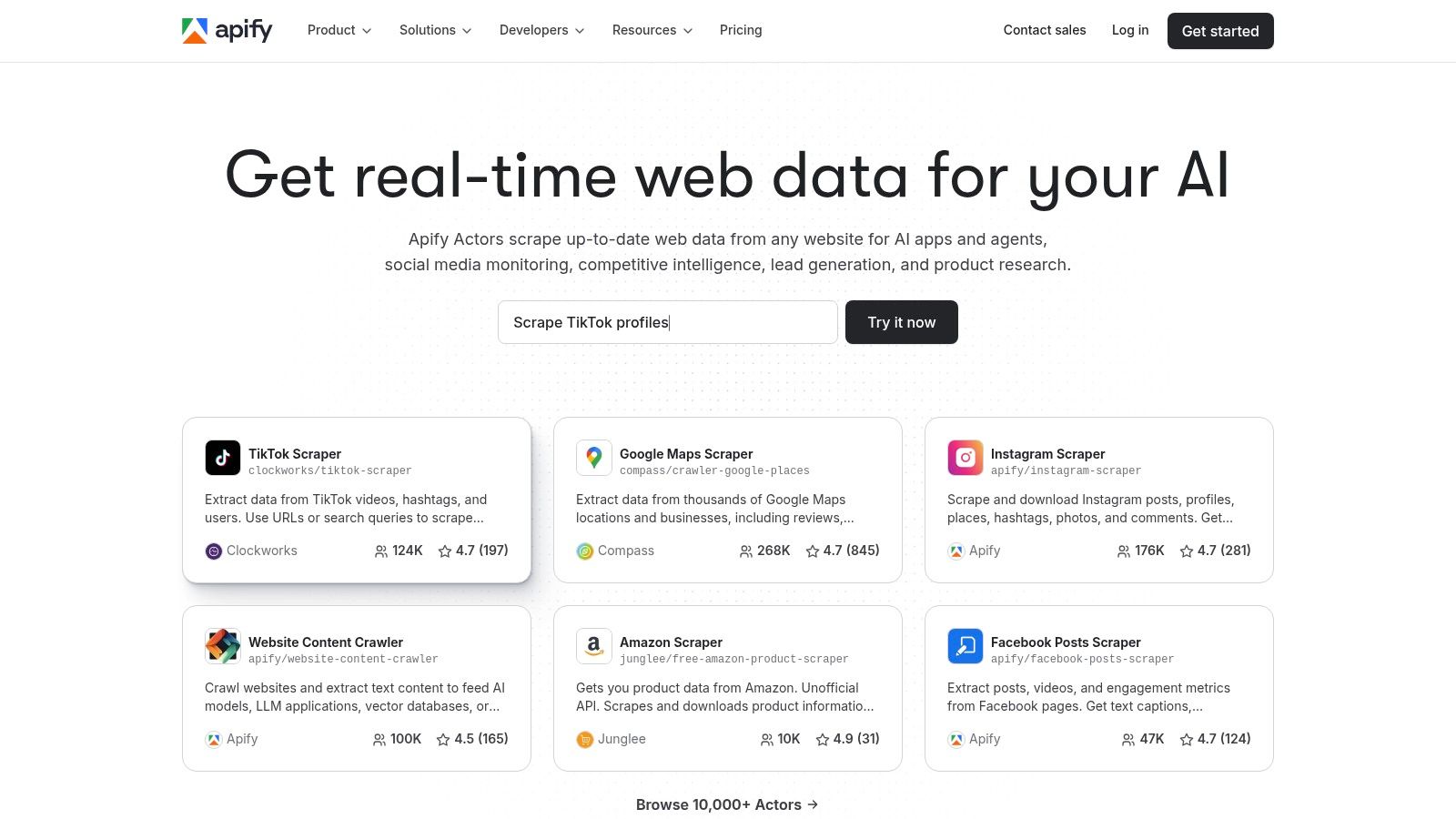
Apify se positionne comme une plateforme de web scraping cloud beaucoup plus technique et flexible que la plupart des outils no-code. Elle s'adresse aussi bien aux développeurs qu'aux utilisateurs non-techniques grâce à sa marketplace d' "Actors", des scripts pré-construits pour extraire des données de sources variées (Google Maps, SERP, sites e-commerce, réseaux sociaux, etc.). Sa force réside dans sa capacité à gérer des opérations de scraping à grande échelle avec une infrastructure robuste, incluant des proxys et une orchestration avancée.
La plateforme permet soit d'utiliser des solutions clé-en-main depuis le store, soit de développer ses propres scrapers en Node.js et de les héberger sur l'infrastructure Apify. Cette dualité en fait un outil puissant pour les entreprises ayant des besoins complexes ou évolutifs, passant d'une simple extraction à une automatisation industrielle. La facturation, basée sur des "Compute Units" (CU), offre une grande flexibilité mais demande une courbe d'apprentissage pour optimiser les coûts.
Caractéristiques et positionnement
Apify se distingue par son approche orientée développeur et sa scalabilité quasi-illimitée. C'est un des rares outils de scraping qui combine un store d'applications prêtes à l'emploi avec un environnement de développement complet pour des projets sur mesure. L'écosystème, avec sa documentation et son académie, est très bien fourni.
- Idéal pour : Les équipes techniques, les data scientists et les entreprises avec des besoins de scraping massifs et personnalisés.
- Fonctionnalités clés : Marketplace d'Actors, développement de scrapers personnalisés, gestion de proxys intégrée, planification et orchestration (webhooks, API), exécution dans le cloud.
- Limites à considérer : La courbe d'apprentissage est plus raide que pour les outils purement no-code. Le modèle de tarification basé sur l'usage (Compute Units) peut devenir complexe à maîtriser et potentiellement coûteux pour des tâches mal optimisées.
Le plan gratuit est généreux et permet de tester en profondeur la plateforme avant de s'engager sur un plan payant, qui fonctionne sur un système de crédits prépayés et de paiement à l'usage.
Site web : https://apify.com
5. Zyte (ex-Scrapinghub)
Zyte, anciennement connu sous le nom de Scrapinghub, est une plateforme de scraping web destinée aux développeurs et aux entreprises ayant des besoins d'extraction de données à grande échelle et techniquement complexes. Cet outil de scraping se positionne comme une solution d'infrastructure complète, offrant une API tout-en-un qui gère la rotation des proxys, le rendu JavaScript et la résolution des CAPTCHAs, évitant ainsi les blocages sur les sites les plus difficiles. C'est la solution de prédilection pour alimenter des applications data-driven.
Contrairement aux outils no-code, Zyte est conçu pour s'intégrer dans un flux de travail de développement. Il est particulièrement puissant lorsqu'il est utilisé avec des frameworks de scraping open-source comme Scrapy (maintenu par Zyte), Playwright ou Puppeteer. Le développeur se concentre sur la logique d'extraction (quelles données récupérer), tandis que l'API de Zyte gère toute la complexité liée à l'accès fiable et ininterrompu à la source de données.
Caractéristiques et positionnement
Zyte se distingue par sa robustesse et sa fiabilité à l'échelle de la production. Son modèle de tarification est unique, basé sur le nombre de requêtes réussies et des paliers de complexité, ce qui garantit que l'on ne paie que pour les données effectivement obtenues.
- Idéal pour : Les entreprises et les équipes techniques qui ont besoin d'une infrastructure de scraping fiable pour des projets critiques ou à gros volume.
- Fonctionnalités clés : API d'extraction intelligente, gestionnaire de proxys performant (Smart Proxy Manager), rendu JavaScript complet, capacités d'unblocking avancées, intégration native avec Scrapy.
- Limites à considérer : L'approche est purement technique et nécessite des compétences en développement. Le modèle de tarification, bien que juste, demande une bonne compréhension des paliers de complexité pour optimiser les coûts sur des sites web variés.
Cette solution est moins adaptée aux équipes marketing ou commerciales sans support technique, mais elle est inégalée pour ceux qui construisent des produits basés sur des données web à grande échelle.
Site web : https://www.zyte.com
6. Bright Data
Bright Data n'est pas un outil de scraping classique, mais plutôt une plateforme complète d'infrastructure de données web. Elle est reconnue pour fournir l'un des plus grands et des plus fiables réseaux de proxys au monde, ce qui en fait un allié indispensable pour les opérations de scraping à grande échelle ou sur des sites web très protégés. La plateforme s'adresse à des utilisateurs plus techniques qui ont besoin d'un contrôle total sur la manière dont ils collectent les données, en évitant les blocages et les captchas.
Au-delà des proxys (résidentiels, ISP, datacenter), Bright Data propose des solutions plus intégrées comme une API de scraping web ("Web Scraper API") qui gère automatiquement la rotation d'IP, les user-agents et les mécanismes de déblocage. Cela permet aux développeurs de se concentrer sur l'analyse des données plutôt que sur la maintenance de l'infrastructure d'extraction. La plateforme dispose également d'une marketplace de datasets pré-collectés pour ceux qui souhaitent accéder directement à des données structurées.
Caractéristiques et positionnement
Bright Data se positionne comme une solution premium et robuste pour l'accès aux données web. Son infrastructure est conçue pour garantir un taux de succès élevé, même sur des cibles complexes. Elle est utilisée par des entreprises qui considèrent la donnée web comme un actif stratégique critique.
- Idéal pour : Les entreprises avec des besoins de scraping intensifs et les équipes techniques qui développent leurs propres scrapers mais ont besoin d'une infrastructure de proxys fiable.
- Fonctionnalités clés : Immense réseau de plus de 150 millions d'IP résidentielles, Web Unlocker pour contourner les protections, API de scraping, marketplace de datasets.
- Limites à considérer : Le coût peut être significativement plus élevé que celui des autres outils, ce qui le rend moins accessible pour les petites équipes ou les projets ponctuels. Le processus de conformité pour l'activation d'un compte peut être assez strict pour garantir un usage éthique.
Les modèles tarifaires sont flexibles, avec des options de paiement à l'usage (PAYG) et des abonnements mensuels, ce qui permet d'adapter les coûts à l'intensité de l'utilisation.
Site web : https://brightdata.com
7. Oxylabs
Oxylabs est une infrastructure de scraping à grande échelle, qui s'adresse principalement aux entreprises et aux développeurs ayant des besoins importants en matière de collecte de données web. Contrairement aux outils no-code, Oxylabs fournit des solutions plus techniques comme des Scraper APIs et un vaste réseau de serveurs proxy. Son positionnement est clair : offrir une fiabilité, une performance et une scalabilité de niveau entreprise pour des missions de scraping complexes.
La plateforme est conçue pour surmonter les obstacles majeurs du web scraping, tels que les blocages d'IP, les CAPTCHAs et les sites dynamiques nécessitant un rendu JavaScript. Les entreprises l'utilisent pour des cas d'usage avancés comme la veille concurrentielle sur les prix, l'analyse de marché ou la collecte de données sur les pages de résultats des moteurs de recherche (SERP) à très grande échelle.
Caractéristiques et positionnement
Oxylabs se distingue par son approche axée sur la performance et la fiabilité, garantie par des accords de niveau de service (SLA). C'est l'un des outils de scraping les plus robustes pour les projets qui ne peuvent tolérer aucune interruption. Sa facturation au résultat (paiement pour les requêtes réussies uniquement) est également un différenciateur clé.
- Idéal pour : Les entreprises avec des équipes techniques dédiées, les projets de data science et les opérations de scraping à grande échelle qui exigent une disponibilité maximale.
- Fonctionnalités clés : Scraper APIs spécialisées (SERP, e-commerce), rendu JavaScript intégré, contournement des CAPTCHAs, immense catalogue de proxys (résidentiels, datacenter), support technique de niveau entreprise.
- Limites à considérer : La solution est avant tout une API, ce qui la rend moins accessible pour les utilisateurs non techniques. Le coût peut devenir élevé, notamment si une utilisation intensive du rendu JavaScript est nécessaire pour extraire les données.
Oxylabs est une solution premium pour ceux qui ont dépassé les limites des outils plus simples et qui ont besoin d'une infrastructure solide pour alimenter leurs applications en données.
Site web : https://oxylabs.io
8. Octoparse
Octoparse est une solution de web scraping visuelle et "no-code" qui permet de transformer n'importe quel site web en une source de données structurée sans écrire une seule ligne de code. L'outil fonctionne via une application de bureau où l'utilisateur "pointe et clique" sur les éléments qu'il souhaite extraire, construisant ainsi un robot de scraping de manière intuitive. Il est conçu pour gérer des projets variés, de l'extraction de fiches produits sur des sites e-commerce à la collecte d'annonces sur des portails immobiliers.
Sa flexibilité est l'un de ses points forts. Une fois le "crawler" configuré, il peut être exécuté localement sur votre machine ou programmé pour fonctionner dans le cloud, garantissant une collecte de données continue. Octoparse gère également des aspects techniques complexes comme la pagination, les menus déroulants ou le défilement infini, le tout via son interface graphique. Il s'adresse ainsi autant aux débutants qu'aux équipes ayant besoin d'automatiser des extractions récurrentes.
Caractéristiques et positionnement
Octoparse se distingue par son approche visuelle et sa puissance de configuration, le positionnant comme un des outils de scraping les plus accessibles pour les utilisateurs non-techniques. Il propose aussi des services de données clé en main pour les entreprises qui souhaitent externaliser complètement leurs besoins en scraping.
- Idéal pour : Les analystes marketing, les veilleurs concurrentiels et les entreprises ayant besoin d'extraire des données de sites web complexes sans expertise technique.
- Fonctionnalités clés : Interface "point-and-click", exécution cloud planifiée, gestion de la rotation d'IP, solveur de CAPTCHA, nombreux formats d'export (CSV, Excel, API), et intégrations Zapier.
- Limites à considérer : Bien que puissant, il peut être moins agile que des solutions basées sur du code pour des workflows très spécifiques ou des intégrations DevOps poussées. Ses tarifs ont également connu une hausse notable depuis 2024.
Le plan gratuit est généreux pour les petits projets, mais l'exécution dans le cloud et les fonctionnalités avancées comme les proxys sont réservées aux plans payants.
Site web : https://www.octoparse.com
9. ParseHub
ParseHub est un outil de scraping de bureau puissant qui adopte une approche visuelle pour l'extraction de données. Contrairement à de nombreuses plateformes purement cloud, il propose une application à installer qui permet de cliquer directement sur les éléments d'une page web pour construire un scénario d'extraction. Cette méthode le rend particulièrement efficace pour gérer des sites complexes avec du JavaScript, du défilement infini, des pop-ups et des systèmes de pagination.
L'utilisateur "enseigne" à ParseHub comment naviguer et quelles données collecter en effectuant des actions dans une interface interactive. Une fois le projet configuré, il peut être exécuté dans le cloud de manière programmée, avec des fonctionnalités avancées comme la rotation d'adresses IP pour éviter les blocages. Cette combinaison entre une configuration locale visuelle et une exécution cloud automatisée en fait un outil hybride très flexible.
Caractéristiques et positionnement
ParseHub se positionne comme une solution robuste pour ceux qui trouvent les extensions de navigateur trop limitées mais ne souhaitent pas écrire de code. Son point fort est sa capacité à gérer l'interactivité des sites modernes sans effort de programmation.
- Idéal pour : Les analystes de données, les marketeurs et les développeurs qui ont besoin d'extraire des données de sites dynamiques et complexes de manière fiable.
- Fonctionnalités clés : Éditeur visuel pour créer des scénarios (clic, scroll, pagination, formulaires), exécution cloud planifiée, rotation d'IP intégrée, API REST pour un contrôle programmatique, et intégrations avec des services de stockage comme S3 ou Dropbox.
- Limites à considérer : La courbe d'apprentissage est un peu plus élevée que pour des outils plus simples. De plus, bien qu'il existe un plan gratuit, il est assez limité en termes de vitesse et de pages par exécution, et les plans payants peuvent être coûteux pour les PME.
Le plan gratuit est excellent pour se familiariser avec l'outil et pour des petits projets ponctuels, mais une utilisation intensive nécessitera rapidement de passer à une offre supérieure.
Site web : https://www.parsehub.com
10. Web Scraper (webscraper.io)
Web Scraper est un des outils de scraping les plus accessibles du marché, commençant sa vie comme une simple mais puissante extension Chrome. Son principal avantage est sa capacité à permettre aux utilisateurs de créer des "sitemaps" directement depuis leur navigateur pour définir comment un site doit être parcouru et quelles données extraire, sans écrire une seule ligne de code. L'extension est idéale pour des projets de petite à moyenne envergure ou pour prototyper rapidement une logique d'extraction.
Pour des besoins plus importants, la plateforme propose Web Scraper Cloud. Cette version payante permet d'exécuter les scrapers créés avec l'extension à plus grande échelle. Elle gère la planification des tâches, l'exécution parallèle de plusieurs scrapers, la rotation d'adresses IP et le rendu JavaScript, ce qui est indispensable pour les sites web modernes et dynamiques. Cette approche hybride (extension gratuite et cloud payant) offre une grande flexibilité.
Caractéristiques et positionnement
Web Scraper se positionne comme un point d'entrée idéal pour ceux qui débutent dans le scraping, tout en offrant une voie claire vers la montée en charge. L'interface visuelle de création de "sitemaps" est intuitive : l'utilisateur clique sur les éléments à scraper pour construire sa recette.
- Idéal pour : Les freelances, les petites équipes et les analystes qui ont besoin d'un outil visuel pour des extractions ciblées sans engagement initial.
- Fonctionnalités clés : Extension de navigateur gratuite, interface de type "point-and-click", gestion de la pagination, extraction de données depuis des sites dynamiques (AJAX), et service Cloud pour l'automatisation.
- Limites à considérer : L'extension gratuite est limitée par les ressources de votre propre ordinateur et votre adresse IP. Pour des sites très complexes ou une collecte à grande échelle, la version Cloud devient nécessaire, et les coûts peuvent augmenter, notamment si vous ajoutez l'option de proxy résidentiel qui est facturée séparément.
Le modèle freemium est très généreux et permet de se familiariser complètement avec l'outil avant d'envisager de passer à une formule payante pour des besoins plus poussés.
Site web : https://webscraper.io
11. Data Miner
Data Miner est une extension de navigateur (Chrome/Edge) qui se positionne comme l'un des outils de scraping les plus accessibles pour les extractions rapides. Il permet de transformer n'importe quelle page web en une source de données structurées en quelques clics. Son fonctionnement repose sur un système de "recettes" (recipes), qui sont des configurations prédéfinies pour extraire des informations spécifiques comme des listes de produits, des contacts ou des tableaux de données.
Les utilisateurs peuvent choisir parmi des milliers de recettes publiques créées par la communauté ou créer leurs propres recettes privées pour des besoins spécifiques. L'outil est particulièrement efficace pour des tâches ponctuelles : capturer une liste de participants à un événement, extraire les résultats d'une recherche sur un annuaire, ou récupérer des informations depuis des pages de résultats. Il gère également l'automatisation de la pagination (clic sur "page suivante") et peut exporter directement les données vers des fichiers CSV ou Google Sheets.
Caractéristiques et positionnement
Data Miner se distingue par sa simplicité et son intégration directe au navigateur, rendant le scraping visuel et intuitif. Il ne nécessite aucune infrastructure cloud ou configuration complexe, ce qui le rend idéal pour des extractions ciblées et rapides.
- Idéal pour : Les freelances, PME et équipes commerciales ayant besoin d'extraire rapidement des listes B2B depuis leur navigateur sans engagement technique.
- Fonctionnalités clés : Extension navigateur, catalogue de recettes publiques, création de recettes privées, automatisation de la pagination, export CSV et Google Sheets, possibilité d'injection de JavaScript personnalisé.
- Limites à considérer : Le compte gratuit est limité à 500 pages par mois, et une fois cette limite atteinte, l'outil est bloqué jusqu'au renouvellement. Il peut s'avérer moins robuste que des solutions cloud pour scraper des sites très dynamiques ou protégés contre le scraping.
Les plans payants restent très abordables, et la société propose des services de création de recettes sur mesure ainsi que des formations, ce qui en fait une solution évolutive pour les petites structures.
Site web : https://dataminer.io
12. ScrapingBee
ScrapingBee est une API de web scraping conçue pour les développeurs qui souhaitent externaliser la complexité technique de l'extraction de données. Cet outil de scraping, édité par une société française, se concentre sur la simplification du processus en gérant les aspects les plus fastidieux : la rotation des proxys, le rendu des pages JavaScript (sites "single-page application") et le contournement des blocages. Au lieu de construire et maintenir une infrastructure complexe, les développeurs peuvent faire un simple appel API pour récupérer le contenu HTML propre d'une page.
L'approche est résolument technique, visant à s'intégrer directement dans des applications ou des scripts personnalisés (Python, JS, etc.). ScrapingBee propose également des endpoints spécialisés, notamment pour les résultats de recherche Google, ce qui permet d'extraire des données SERP sans se soucier des blocages fréquents de Google. La solution est donc pensée pour la fiabilité et la scalabilité des opérations de collecte de données.
Caractéristiques et positionnement
ScrapingBee se distingue par sa simplicité d'intégration pour un public technique et son excellent rapport volume/prix. C'est une solution "headless browser as a service" qui évite aux équipes de devoir gérer elles-mêmes des instances de Puppeteer ou Selenium. Le support client, basé en France, est également un atout pour les entreprises françaises.
- Idéal pour : Les développeurs et les startups qui ont besoin d'une brique de scraping fiable à intégrer dans leurs propres produits ou workflows de données.
- Fonctionnalités clés : API avec gestion de proxys et rendu JavaScript, géociblage, endpoints dédiés (Google Search), add-ons pour les captures d'écran et l'extraction de données structurées.
- Limites à considérer : L'outil est exclusivement une API, il n'y a donc aucune interface "no-code" pour les profils non techniques. Le modèle est basé sur des abonnements mensuels, ce qui peut être moins flexible qu'une facturation purement à l'usage pour des besoins très ponctuels.
Les plans sont basés sur un système de crédits API, permettant une grande flexibilité en fonction du volume de requêtes nécessaires, ce qui en fait l'un des outils de scraping les plus adaptables pour les projets en croissance.
Site web : https://www.scrapingbee.com
Comparatif des 12 meilleurs outils de scraping
| Produit | Caractéristiques clés | Qualité (★) | Valeur / Prix (💰) | Public cible (👥) | Différenciateurs (✨) |
|---|---|---|---|---|---|
| Scraap.ai 🏆 | No‑code, extraction multi‑sources, enrichissement & scoring en temps réel, 50+ templates, intégrations CRM | ★★★★★ | 💰 Essai 50 crédits, tarification sur demande, ROI rapide | 👥 SDRs, growth, Sales Ops, fondateurs | ✨ No‑code ultra‑accessible, conformité FR (ISO/SOC/RGPD), anti‑bot avancé |
| PhantomBuster | Automations no‑code, >100 "Phantoms", cloud scheduling, exports | ★★★★☆ | 💰 Plans abordables, quotas d'exécution mensuels | 👥 Growth, SDRs, freelancers | ✨ Déploiement rapide, workflows multi‑étapes |
| Captain Data | API Search/Enrich (people/company), chaînes LinkedIn, intégrations CRM | ★★★★☆ | 💰 Tarification à la consommation (crédits), dégressif | 👥 Sales Ops, RevOps, équipes data | ✨ API temps réel, monitoring d'intent, support volumes |
| Apify | Marketplace d'Actors, bots prêts ou personnalisables, orchestration, proxys | ★★★★☆ | 💰 Prépayé + pay‑as‑you‑go, flexible selon usage | 👥 Devs, équipes tech, entreprises | ✨ Catalogue large, customisation à l'échelle |
| Zyte (ex‑Scrapinghub) | API extraction/unblocking, Smart Proxy Manager, rendu JS, CAPTCHA | ★★★★☆ | 💰 Facturation par 1k réponses selon complexité | 👥 Devs, équipes production | ✨ Très bon taux de succès sur sites protégés |
| Bright Data | Réseau 150M+ IP résidentielles, Web Scraper API, marketplace datasets | ★★★★☆ | 💰 Puissant mais souvent plus onéreux; KYC possible | 👥 Grandes entreprises, data teams | ✨ Couverture IP massive, outils d'unblocking avancés |
| Oxylabs | Scraper APIs, bypass CAPTCHA, rotation IP, SLAs enterprise | ★★★★☆ | 💰 Tarification au résultat, adapté gros volumes | 👥 Entreprises, équipes dev/ops | ✨ Performance & SLA pour usages à grande échelle |
| Octoparse | Interface visuelle desktop + cloud, planification, exports multiples | ★★★★☆ | 💰 Plans cloud + add‑ons (proxys, CAPTCHA) | 👥 Non‑tech, PME, agences | ✨ Très accessible, services data gérés |
| ParseHub | Éditeur scénarios (scroll/pagination/actions), scheduling, IP rotation | ★★★☆☆ | 💰 Plans Standard/Pro plus coûteux | 👥 Utilisateurs non‑tech à intermédiaires | ✨ Bon pour scénarios complexes sans code |
| Web Scraper (webscraper.io) | Extension Chrome + Web Scraper Cloud, rendu JS, planning | ★★★★☆ | 💰 Essai Cloud 7j, scale rentable sur plans supérieurs | 👥 Utilisateurs browser‑centric, freelancers | ✨ Extension gratuite pour prototypage + Cloud scale |
| Data Miner | Extension Chrome/Edge, recettes publiques/privées, connexion Sheets | ★★★☆☆ | 💰 Plans abordables, gratuit limité (500 pages/mois) | 👥 PME, freelancers | ✨ Rapide pour listes B2B simples, recettes & trainings |
| ScrapingBee | API managée (rendu JS, proxys, géociblage), endpoints SERP | ★★★★☆ | 💰 Bon rapport volume/prix pour startups, paliers credits | 👥 Devs, startups, intégrateurs FR | ✨ API simple à intégrer, support local (France) |
Comment choisir le bon outil de scraping pour votre stratégie B2B ?
Le voyage à travers l'écosystème des outils de scraping révèle une vérité essentielle : il n'existe pas de solution universelle. La plateforme parfaite pour une startup agile peut s'avérer inadaptée pour une entreprise avec des besoins de données à grande échelle. Le choix final dépend d'un alignement stratégique entre vos objectifs commerciaux, vos ressources techniques internes et, bien sûr, votre budget.
Nous avons exploré un large éventail de solutions, des plateformes no-code conviviales aux API robustes pour les développeurs. Il est maintenant temps de synthétiser ces informations pour vous guider vers la décision la plus éclairée.
Synthèse des profils d'utilisateurs et des outils correspondants
Pour clarifier votre choix, identifions les grands profils d'utilisateurs et les catégories d'outils qui leur sont le mieux adaptées :
-
Pour les équipes commerciales et SDR (sans compétences techniques) : L'objectif est simple : générer rapidement des listes de prospects qualifiés et les intégrer dans un CRM. La simplicité, l'automatisation et un workflow complet sont primordiaux.
- Recommandations clés : Scraap.ai est spécifiquement conçu pour ce cas d'usage, en intégrant l'extraction, l'enrichissement et la qualification dans une interface intuitive. PhantomBuster est également un excellent choix pour l'automatisation des tâches sur les réseaux sociaux.
-
Pour les Growth et RevOps Managers (avec une appétence technique) : Ces profils cherchent à construire des machines de croissance sophistiquées. Ils ont besoin de flexibilité, de capacités d'intégration avancées et d'un contrôle granulaire sur les flux de données.
- Recommandations clés : Captain Data et Apify offrent un excellent équilibre entre des modèles prédéfinis et la possibilité de créer des workflows complexes. Leurs intégrations API les rendent parfaits pour alimenter des systèmes internes.
-
Pour les développeurs et les équipes Data : La priorité est la performance, la fiabilité et la capacité à contourner les blocages à grande échelle. La gestion des proxys, des CAPTCHAs et la scalabilité sont des préoccupations centrales.
- Recommandations clés : Des solutions comme Bright Data, Oxylabs, Zyte ou ScrapingBee fournissent l'infrastructure sous-jacente (proxys, API) nécessaire pour construire des solutions de scraping sur mesure et robustes.
Les critères de décision finaux à ne pas négliger
Au-delà du profil utilisateur, plusieurs facteurs transversaux doivent peser dans votre évaluation. Ne finalisez pas votre choix avant d'avoir considéré ces points :
- Conformité et Éthique : La conformité au RGPD n'est pas une option. Privilégiez les outils qui sont transparents sur leurs méthodes de collecte et qui vous aident à respecter la réglementation, notamment en se concentrant sur les données publiques et professionnelles.
- Qualité et Fraîcheur des données : Un outil qui extrait des données obsolètes ou incorrectes est contre-productif. Cherchez des plateformes qui incluent des étapes de vérification et d'enrichissement pour garantir que vos listes de prospects sont fiables et à jour.
- Scalabilité et Tarification : Votre besoin de données va-t-il croître ? Assurez-vous que le modèle de tarification de l'outil peut évoluer avec vous sans devenir prohibitif. Analysez bien les limites sur le volume de données, le temps d'exécution ou le nombre de tâches.
- Support et Documentation : Lorsque vous rencontrez un blocage, un support client réactif et une documentation claire peuvent vous faire gagner un temps précieux. C'est un critère souvent sous-estimé mais crucial pour une adoption réussie.
En fin de compte, le meilleur outil de scraping est celui qui s'intègre naturellement dans votre stratégie de croissance et qui vous libère du temps pour vous concentrer sur ce qui compte vraiment : établir des relations et conclure des ventes. Le scraping n'est pas une fin en soi ; c'est un puissant catalyseur pour alimenter votre moteur commercial avec des données de haute qualité. En choisissant judicieusement, vous ne faites pas qu'adopter une nouvelle technologie, vous investissez dans une croissance plus intelligente et plus durable.
Prêt à transformer votre prospection avec un outil qui combine puissance, simplicité et conformité ? Découvrez comment Scraap.ai peut automatiser la génération de vos listes de prospects qualifiés en quelques clics, vous permettant de vous concentrer sur la vente. Lancez votre premier scraping en moins de 5 minutes sur Scraap.ai.


